Enterprise Search is becoming one of the common requirements of any consumer web application that we build these days. So I thought of learning some stuff in this domain. If you think about open source frameworks providing enterprise search functionality, probably Lucene is the one and only answer that comes to your mind. Lucene is a fully featured full text search engine library. Some other platforms and frameworks are developed that leverages core search functionality of Lucene.
Solr is one of such platforms that provide cool features like token highlighting, faceted search and many many more. Solr runs as a standalone search server and can be integrated into the applications using HTTP/XML API. Solr is typically used (or suggested to be used) when the underlying data that you are trying to index doesn’t change often.
Hibernate Search is a framework built on top of Lucene and Hibernate Core. In the following blog post, I would explain how to integrate Hibernate Search into your application.
Introduction
The typical components involved in any Search application are described in the diagram below. The flow is pretty simple, content undergoes some process which makes it searchable and end users can benefit from it. The steps marked in green are taken care by Lucene Core library. Lucene expects content in specific format called Document. Given this component stack, if you need to build any search application, the steps involved would be to convert the content into Lucene understandable Document format for indexing and during the search operation, mapping the results into POJO’ which could be used by the presentation layer to display the search results. Apart from this, another challenge involved in building search applications is keeping the content and index in sync. This step is crucial, as failure to do so might result in false or stale search results. I hope you can imagine the consequences of this. If the content is available in database, then frameworks such as Hibernate Search and Compass takes care of these operations and makes indexing and searching almost a cake walk for a developer (at this point I’ve no clue about performance and scalability aspects). These frameworks are designed to provide indexing and searching features directly for entities which saves additional conversion steps. In the post below, we would try to understand how Hibernate Search does it for you.
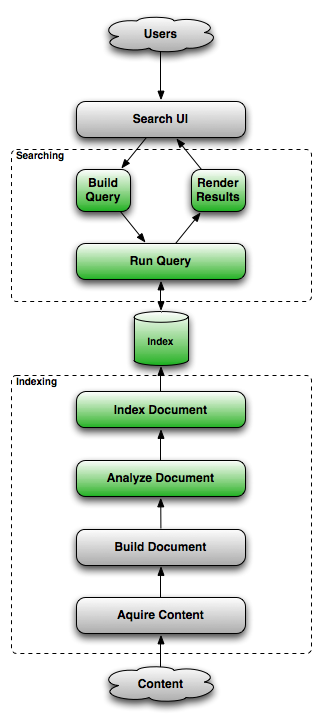
Sample Application
I created a simple Book Store application using Wicket and Spring Hibernate stack. It provides screens for Books maintenance and a search screen. You can checkout the sources from:
svn checkout http://arunoday.googlecode.com/svn/trunk/bookstore arunoday-read-only
To run the application: mvn jetty:run or use Start.java
Maven Dependencies
To integrate Hibernate Search into your application, following maven dependencies are required.
<!-- Hibernate Dependencies -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>3.5.1-Final</version>
</dependency>
<!-- Use JPA -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>3.5.1-Final</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-search</artifactId>
<version>3.2.0.Final</version>
</dependency>
Configuration
Once you have configured the maven dependencies, next step is to configure Hibernate Search specific properties. As part of indexing process, Lucene stores its indexes. We need to configure the type of storage mechanism to be used.
<persistence-unit name="bookstore" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<property name="hibernate.cache.use_second_level_cache"
value="false" />
<property name="hibernate.cache.use_query_cache" value="false" />
<!-- Hibernate Search Configurations -->
<property name="hibernate.search.default.directory_provider"
value="org.hibernate.search.store.FSDirectoryProvider" />
<property name="hibernate.search.default.indexBase" value="tmp/lucene/indexes" />
</properties>
</persistence-unit>
In the above configurations, we are using a File Store to maintain the indexes. Another option is to use RAMDirectoryProvider which stores the indexes in memory. It provides a faster access but its not persistent. So you have to re-index your data if the JVM crashes. That’s pretty much it for basic configurations.
Making Entities Searchable
Next step is to make our entities searchable. To achieve this, we need to annotate the entity with @Indexed annotation and the fields that we want to be a part of Index should be marked with @Field annotation.
@Entity
@Table(name = "book")
@Indexed
@AnalyzerDef(name = "customanalyzer", tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class), filters = {
@TokenFilterDef(factory = LowerCaseFilterFactory.class))
public class Book extends BasicEntity {
@Column(name = "title")
@NotNull
@Size(min = 5, max = 30)
@Field(index = Index.TOKENIZED, store = Store.NO)
@Analyzer(definition = "customanalyzer")
private String title;
The index = Index.TOKENIZED would break the title into individual words. The store = Store.NO would make sure the data is not stored in the index. If your application needs to fetch the entire object graph then you mark the fields with Store.NO. But if you need to use Projections, then its mandatory that the fields used in projection are stored in index. This increases the index size, but saves the database roundtrip. In Lucene, all indexed fields have to be represented as Strings. Hibernate does the conversion for most of the data types. For converting Date, @DateBridge annotation is to be used.
Another important concept is analyzer. Typically the text that is indexed is broken into series of atomic elements. Different types of operations are involved during tokenization e.g. lowercasing the text, removing punctuation marks, etc. Selecting the right analyzer is an important design decision. In the sample we use simple StandardTokenizer that does the basic analysis for us.
Indexing Exiting Data
If the entities are persisted, updated, deleted using Hibernate / JPA, then Hibernate Search framework takes care of synching up the lucene indexes. But if you have already created some data and trying to integrate Hibernate Search later in the development phase, then creating indexes for this existing data is not tough.
FullTextEntityManager fullTextEntityManager = Search.getFullTextEntityManager(entityManager);
try {
fullTextEntityManager.createIndexer().startAndWait();
}
catch (InterruptedException e) {
logger.error("Indexing of data failed", e);
}
Searching Content
One of the powerful features of Hibernate Search is the ability to execute lucene queries and retrieving Hibernate managed entities.
public List<Book> findBooks(String searchToken) {
FullTextEntityManager fullTextEntityManager = Search.getFullTextEntityManager(getEntityManager());
// create native Lucene query
String[] fields = new String[] { "title", "authors.name", "publishingDate" };
QueryParser parser = new MultiFieldQueryParser(Version.LUCENE_29, fields, new StandardAnalyzer(
Version.LUCENE_29));
Query luceneQuery = null;
try {
luceneQuery = parser.parse(searchToken);
}
catch (ParseException e) {
logger.error("Error during parsing lucene query: " + luceneQuery, e);
}
FullTextQuery persistenceQuery = fullTextEntityManager.createFullTextQuery(luceneQuery, Book.class);
// execute search
return persistenceQuery.getResultList();
}
Conclusion
In the above post I gave a very basic introduction to Hibernate Search. If your application is database driven (contains more CRUD screens than read only views) and if it already uses Hibernate then Hibernate Search integrates nicely with such applications. Some say that its intrusive. But then its again the same old XML vs Annotations debate. If you could happily use Hibernate Annotations then adding few more annotations to make entities searchable shouldn’t be a problem. But for some valid reasons if you are avoiding annotations, then may be you are better off with some other frameworks availble in this domain.